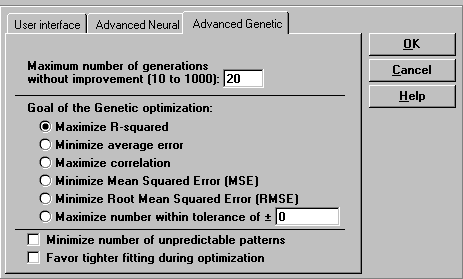
Вкладка Advanced Genetic
Maximum number of generations without improvement (Максимальное количество поколений без улучшений) - позволяет Вам изменить критерий остановки тренировки в режиме генетического обучения, указав максимальное количество поколений, не приволящих к улучшению модели. Количество поколений можно устанавливать в пределах от 10 до 1000 (только целые числа), введя выбранное число в окно редактирования. Чем меньше Вы установите количество поколений, тем меньше будет время обучения. Значение, установленное по умолчанию, равно 100. Вполне вероятно, что Вам захочется уменьшить это число, если при тренировке нескольких похожих моделей Вы заметите, что лучшая модель уже достигается к моменту, когда улучшения не происходит, скажем, после 20 поколений.
Goal of the Genetic optimization (Цель генетической оптимизации): При генетической стратегии тренировки Вы можете указать различные цели генетической оптимизации:
- Maximize R-Squared - максимизация критерия R квадрат (общепринятый статистический коэффициент)
- Minimize average error - минимизация абсолютной средней ошибки (разности между действительными и предсказанными значениями)
- Maximize correlation - максимизация коэффициента линейной корреляции между действительными и предсказанными значениями
- Minimize Mean Squared Error (MSE) - минимизация среднего квадрата ошибки (разности между действительными и предсказанными значениями)
- Minimize Root Mean Squared Error (RMSE) - минимизация среднеквадратичной ошибки (квадратного корня из среднего квадрата ошибки)
- Maximize number within tolerance - максимизация процента предсказаний, совпадающих с действительными значениями с заданной точностью (например, лежащих в диапазоне [действительное значение ± 1,5])
Заметим, что при выборе цели "максимизация R квадрат" будет создана такая же сеть, как и при выборе в качестве цели минимизации среднего квадрата ошибки MSE. Выбор цели здесь зависит просто от того, какой из данных статистических показателей Вам больше по душе. Заметим также, что методы тренировки с использованием остальных целей примерно одинаковы и зачастую приводят к одним и тем же результатам. Например, минимизация RMSE подобна минимизации MSE, но не является точно тем же самым. Мы не можем указать, выбор какого статистического показателя является лучшим в общем случае или даже при решении какой-либо частной задачи. Пользователю следует вручную определить метод, который дает лучший результат. Тем не менее, приведем несколько общих соображений:
1. Используйте в качестве цели максимизацию коэффициента корреляции, если Вам важнее получить правильное предсказание о направлении изменения некоторой величины, чем о ее абсолютном значении. Например, приведенные ниже предсказанные значения не являются близкими к действительным, но коэффициент корреляции между ними весьма высок (0,9), поскольку росту предсказанных значений соответствует рост действительных, хотя скорости роста отличаются:
| Действительное |
Предсказанное |
|
1 |
1 |
|
1 |
1 |
|
2 |
1.1 |
|
4 |
1.2 |
|
8 |
1.3 |
|
16 |
1.4 |
|
32 |
1.5 |
2. Если Вы хотите, чтобы алгоритм стремился снизить разницу между предсказанными и действительными значениями, Вам следут выбрать одну из следующих целей оптимизации: R-Squared, MSE, RMSE. Если же Вы хотите, чтобы ошибки на каждом примере были сведены к минимуму, используйте в качестве цели минимизацию средней ошибки или максимизацию процента предсказаний с заданной точностью.
3. Если Вы хотите, чтобы алгоритм останавливался в тот момент, когда предсказанные и действительные значения близки, Вам следует использовать максимизацию процента предсказаний с заданной точностью. Этот метод полезен также в тех случаях, когда Вы замечаете, что при использовании других методов наблюдается большое количество плохо предсказанных примеров. Он является единственным методом, при котором плохо предсказанные примеры вызывают "штрафование" целевой функции, даже если не включен режим "Minimize Number of Unpredictable Patterns" - минимизация количества непредсказанных примеров (см. ниже).
Minimize number of unpredictable patterns (Минимизация количества непредсказываемых примеров): Генетический метод имеет встроенную защиту для того, чтобы не делать бессмысленных предсказаний, т.е. алгоритм не будет пытаться сделать предсказание для такого примера (строки данных), для которого в тренировочном наборе отсутствуют данные, близкие к предъявленному примеру. Этот пример будет помечен как N/A, что означает "непредсказываемый", и в процессе тренировки такую метку могут получить несколько примеров. Однако, существует возможность ослабить эту защиту, введя "штрафование" целевой функции генетического алгоритма, когда попадаются непредсказываемые примеры. Для этого надо перед началом тренировки включить флажок "Minimize number of unpredictable patterns".
Favor tighter fitting during optimization (Предпочесть более точное приближение при оптимизации): Иногда генетический метод не может хорошо приблизить предсказания к кривой действительных значений. Это может происходить, когда на кривой отсутствует шум, и лишь небольшое количество из набора переменных определяют предсказание. В таких случаях можно изменить режим тренировки таким образом, чтобы попытаться получить более точное приближение. Для этого необходимо установить флажок "Favor tighter fitting during optimization".
|
 На главную
На главную